How can we diagnose a deep learning computer vision model without a test set?
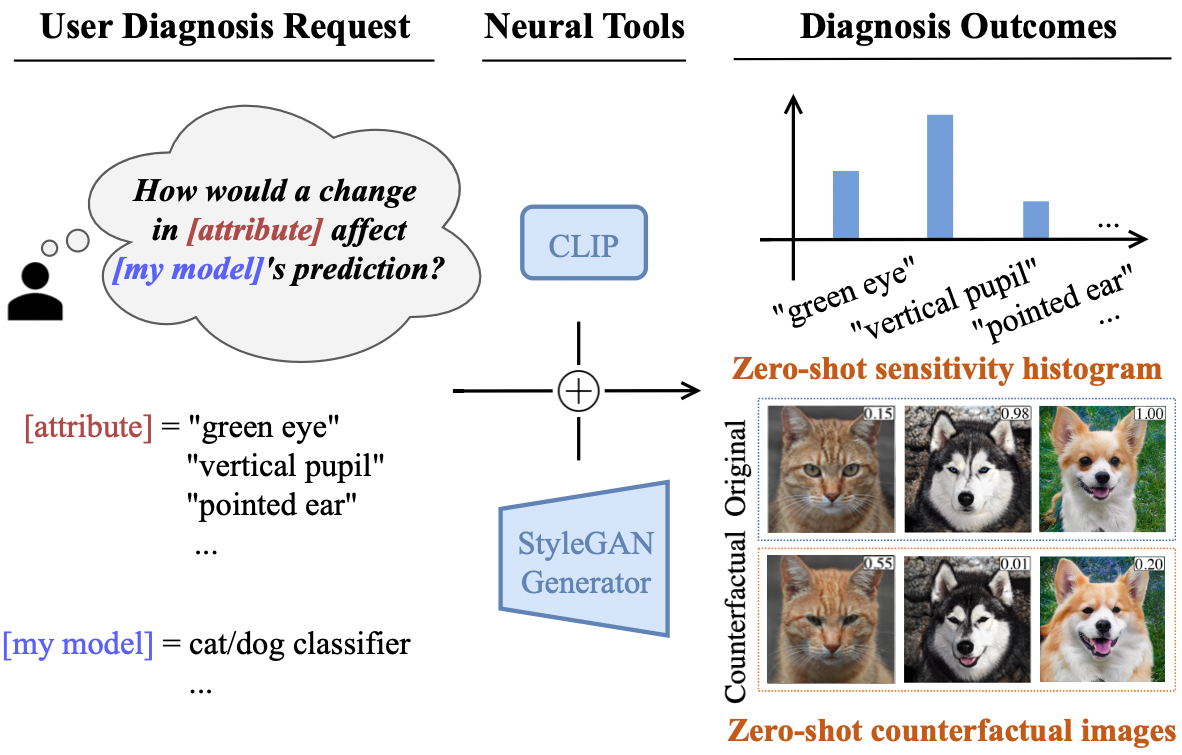
When it comes to deploying deep vision models, the behavior of these systems must be explicable to ensure confidence in their reliability and fairness. A common approach to evaluate deep learning models is to build a labeled test set with attributes of interest and assess how well it performs. However, creating a balanced test set (i.e., one that is uniformly sampled over all the important traits) is often time-consuming, expensive, and prone to mistakes. The question we try to address is: can we evaluate the sensitivity of deep learning models to arbitrary visual attributes without an annotated test set?
This paper argues the case that Zero-shot Model Diagnosis (ZOOM) is possible without the need for a test set nor labeling. To avoid the need for test sets, our system relies on a generative model and CLIP. The key idea is enabling the user to select a set of prompts (relevant to the problem) and our system will automatically search for semantic counterfactual images (i.e., synthesized images that flip the prediction in the case of a binary classifier) using the generative model. We evaluate several visual tasks (classification, key-point detection, and segmentation) in multiple visual domains to demonstrate the viability of our methodology. Extensive experiments demonstrate that our method is capable of producing counterfactual images and offering sensitivity analysis for model diagnosis without the need for a test set.
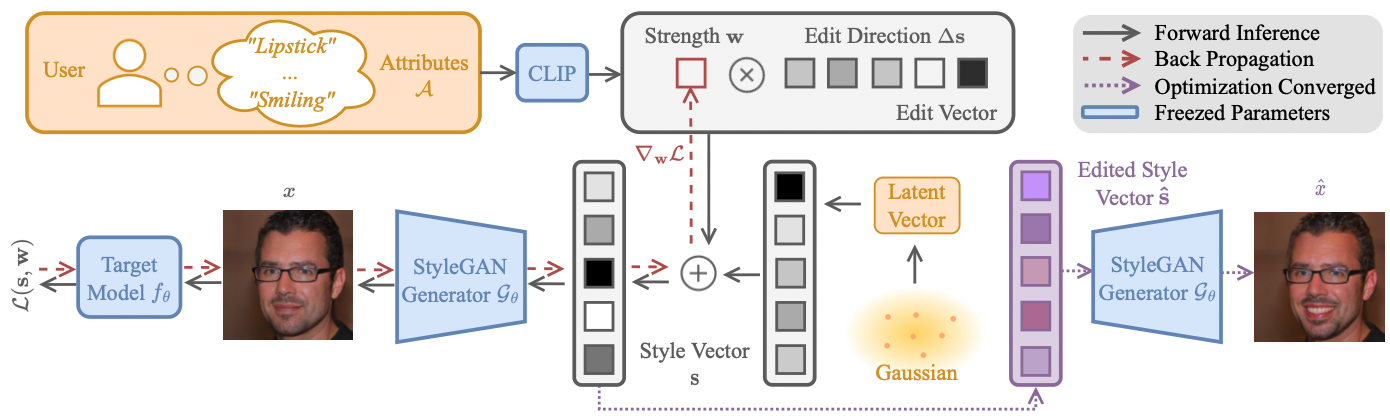
The ZOOM framework. Black solid lines stand for forward passes, red dashed lines stand for backpropagation, and purple dashed lines stands for inference after the optimization converges. The user inputs single or multiple attributes, and we map them into edit directions. Then we assign to each edit direction (attribute) a weight, which represents how much we are adding/removing this attribute. We iteratively perform adversarial learning on the attribute space to maximize the counterfactual effectiveness. More details in the paper.
This demo shows how a classifier score changes with semantic modifications of the image. We refer the images as counterfactual images, as the images are generated to flip the target model, in this case, a classifier.
 |
The first four images are on Dog/Cat classifier, and the following two are on perceived age (Young) classifier. Lastly, the final two are on the perceived gender classifier.
Model diagnosis histograms generated by the counterfactual's effectiveness on the target model for a particular attribute. The vertical axis values reflect the attribute sensitivities calculated by averaging the model probability change over all sampled images. The horizontal axis is the attribute space input by user.
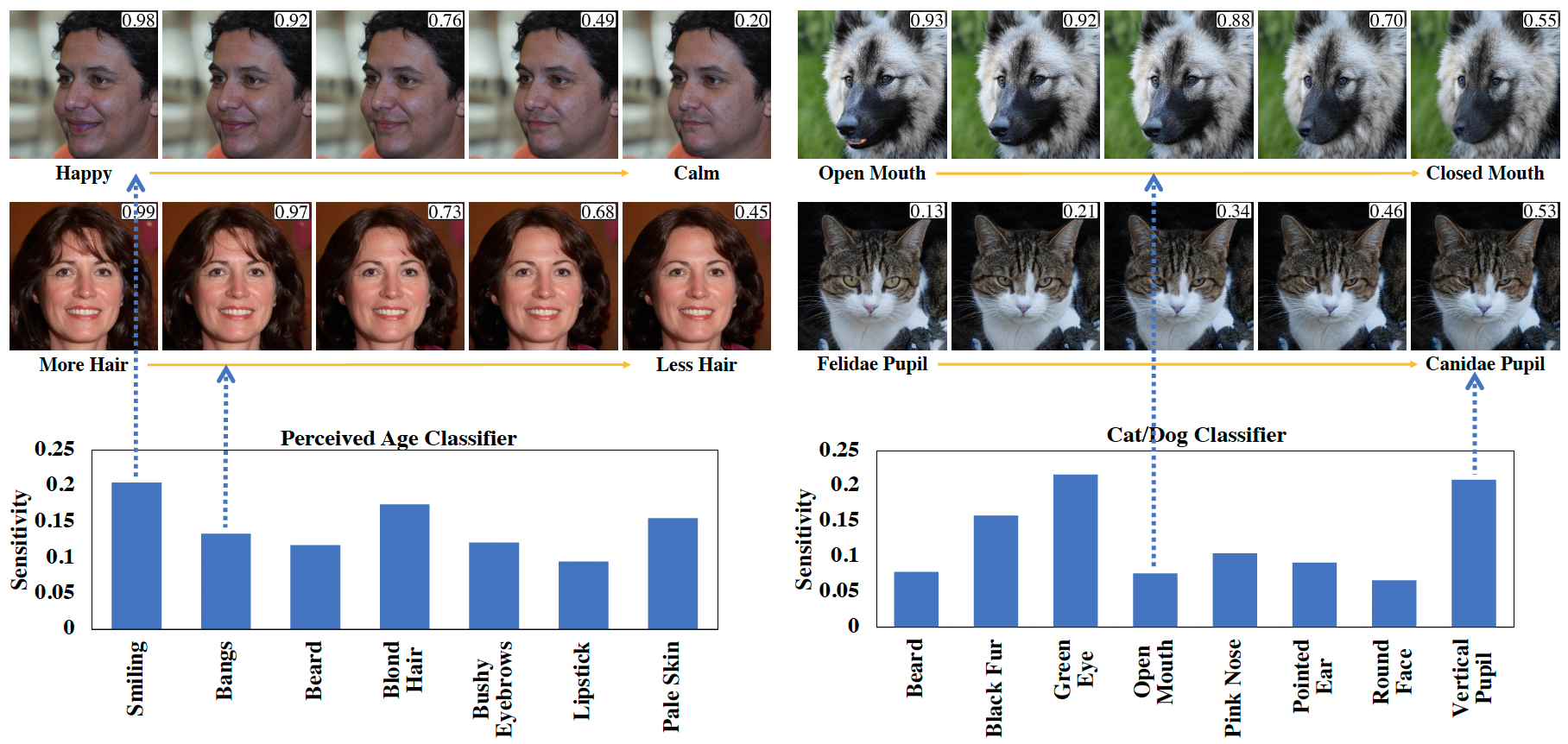
This demo shows the generation of counterfactual images over multiple simultaneous attributes. In the images with a box on the right-up corner, the number indicates the probability of the classifier.

We also show additional counterfactuals examples on other computer vision models, including semantic segmentation, multi-class classification, and binary church classifier (BCC).

@inproceedings{luo2023zeroshot,
title={Zero-shot Model Diagnosis},
author={Jinqi Luo and Zhaoning Wang and Chen Henry Wu and Dong Huang and Fernando De La Torre},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
We would like to thank George Cazenavette, Tianyuan Zhang, Yinong Wang, Hanzhe Hu, Bharath Raj for their invaluable feedbacks and suggestions in paper presentation and experimental design. We sincerely express our gratitude to Ken Ziyu Liu, Jiashun Wang, Bowen Li, and Ce Zheng for their revise and support that improve this work.
